0x01 题目
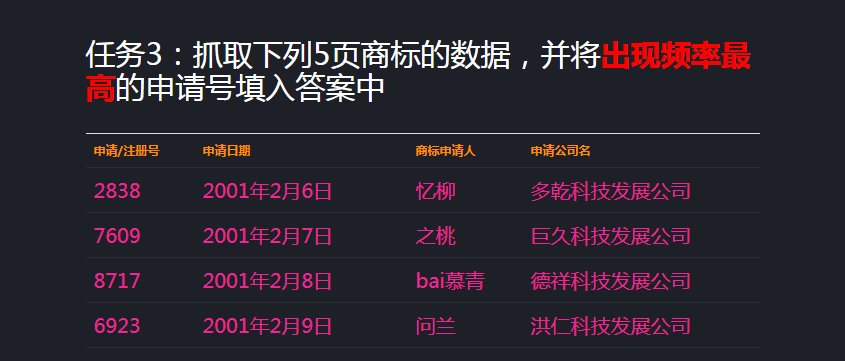
0x02 步骤
1. 查看请求头信息
前几次用谷歌自带分析工具有些包的源码没抓到,这次用了个工具来查看请求,fiddler。
直接启动就能用,它会自动建立代理来抓包。
启动fiddler之后,还是回到chrome中刷新一下页面,然后再fiddler中分析。
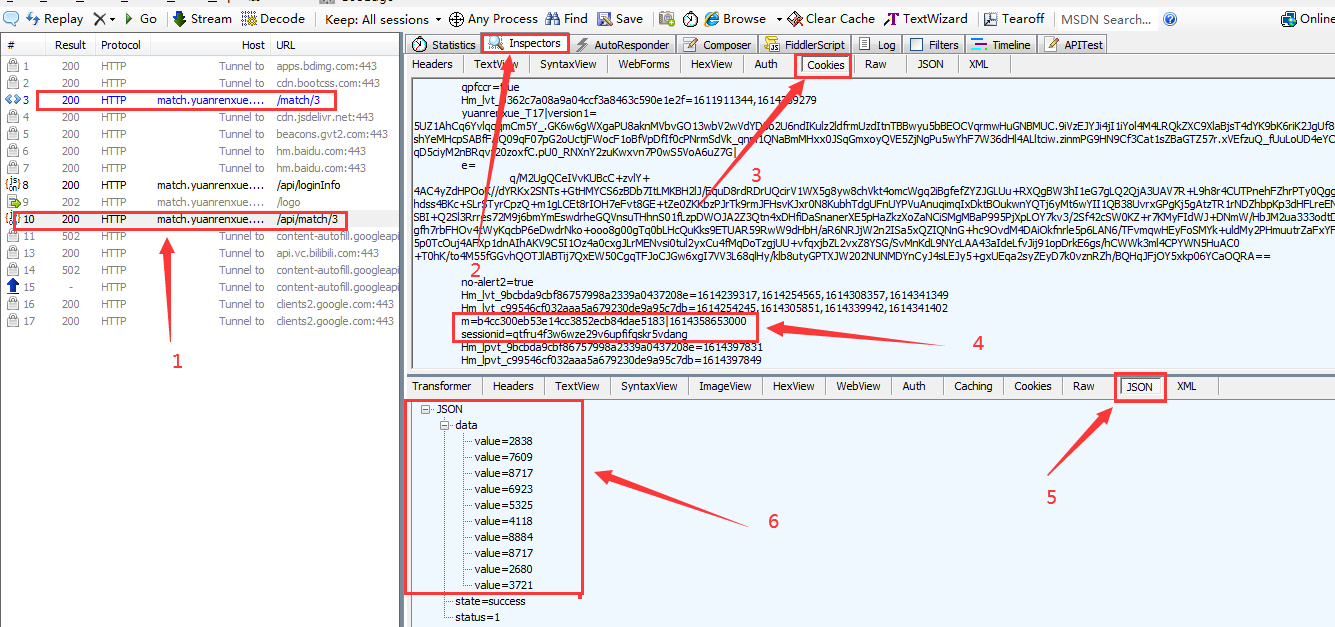
找到获取数据的包(/api/match/3),可以其看到返回包中就是json格式的数据(格式跟以往的题目一样)。
接着看下其请求头,发现cookie处,比较可疑的是m和sessionid,因为全局搜索这两个都是在下面这些包中出现,而且是一模一样的:
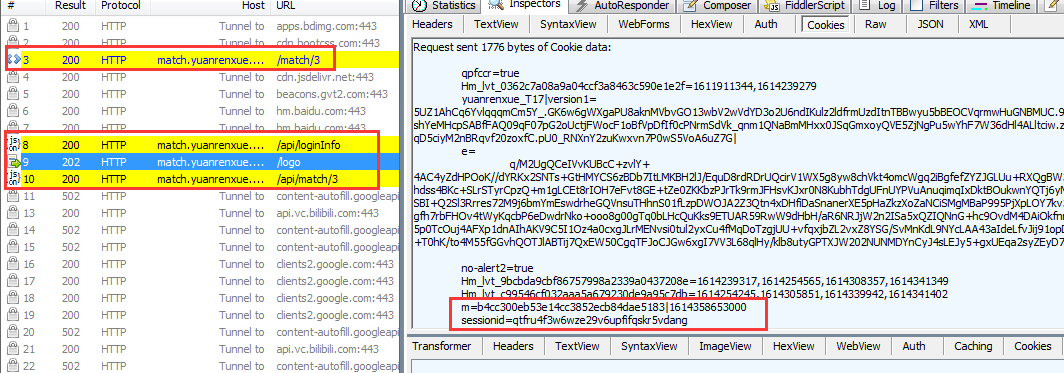
但是m跟时间戳有关,暂时不知道生成规则(在这里测试m浪费了些时间没研究出来,但是后面发现题目提示访问逻辑,所以猜测可能跟生成逻辑没什么关系,而是在访问的时候有什么次序之类的)。那么可以尝试直接带上这两个值向api请求,代码如下:
import requests
url = 'http://match.yuanrenxue.com/api/match/3'
headers = {
'User-Agent': 'yuanrenxue.project',
'Host': 'match.yuanrenxue.com',
'Connection': 'keep-alive',
'Content-Length': '0',
'Accept': '*/*',
'Origin': 'http://match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
'm'
}
response = requests.get(url)
返回了一堆js代码,我花了点时间调试了一下没啥用,这里就不展示了。
2. 换个思路
那么所谓的访问逻辑问题出在哪里呢?观察各个包发现在请求之前还进行了一次访问logo链接,并且我去点击第2页、第3页都会在访问前去访问一次logo链接,所以大胆猜测所谓的访问逻辑可能跟这个有关。
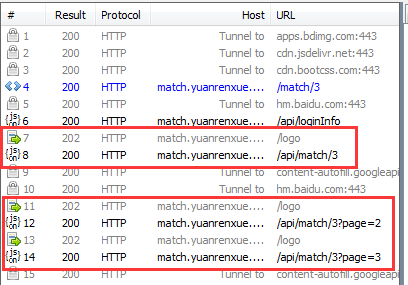
所以接下来先访问logo再请求api,并且因为有sessionid存在,这种有发包先后次序的应该建立session来访问,以保持关联。
3. 编写代码
编写代码如下:
import requests
def get_response(page):
logo_url = 'http://match.yuanrenxue.com/logo'
url = f'http://match.yuanrenxue.com/api/match/3?page={page}'
session = requests.Session()
session.post(logo_url)
response = session.get(url)
print(response.text)
print(response.cookies)
if __name__ == '__main__':
get_response(1)
发现还是不行,带上logo的请求头再试试,顺便把User-Agent改成第4、第5页要求的yuanrenxue.project:
import requests
def get_response(page):
logo_url = 'http://match.yuanrenxue.com/logo'
url = f'http://match.yuanrenxue.com/api/match/3?page={page}'
headers = {
'Host': 'match.yuanrenxue.com',
'User-Agent': 'yuanrenxue.project',
'Connection': 'keep-alive',
'Content-Length': '0',
'Accept': '*/*',
'Origin': 'http://match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'qpfccr=true; Hm_lvt_0362c7a08a9a04ccf3a8463c590e1e2f=1611911344,1614239279; yuanrenxue_T17|version1=5UZ1AhCq6YvlqqqmCm5Y_.GK6w6gWXgaPU8aknMVbvGO13wbV2wVdYD3o2U6ndIKulz2ldfrmUzdItnTBBwyu5bBEOCVqrmwHuGNBMUC.9iVzEJYJi4jI1iYol4M4LRQkZXC9XlaBjsT4dYK9bK6riK2JgUf8shYeMHcpSABfFAQ09qF07pG2oUctjFWocF1oBfVpDfIf0cPNrmSdVk_qnm1QNaBmMHxx0JSqGmxoyQVE5ZjNgPu5wYhF7W36dHl4ALltciw.zinmPG9HN9Cf3Cat1sZBaGTZ57r.xVEfzuQ_fUuLoUD4eYCqD5ciyM2nBRqvf20zoxfC.pU0_RNXnY2zuKwxvn7P0wS5VoA6uZ7G|; e=q/M2UgQCeIVvKUBcC+zvlY+4AC4yZdHPOoK//dYRKx2SNTs+GtHMYCS6zBDb7ItLMKBH2lJ/EquD8rdRDrUQcirV1WX5g8yw8chVkt4omcWgq2iBgfefZYZJGLUu+RXQgBW3hI1eG7gLQ2QjA3UAV7R+L9h8r4CUTPnehFZhrPTy0Qgghdss4BKc+SLrSTyrCpzQ+m1gLCEt8rIOH7eFvt8GE+tZe0ZKKbzPJrTk9rmJFHsvKJxr0N8KubhTdgUFnUYPVuAnuqimqIxDktBOukwnYQTj6yMt6wYII1QB38UvrxGPgKj5gAtzTR1rNDZhbpKp3dHFLreENSBI+Q2Sl3Rrres72M9j6bmYmEswdrheGQVnsuTHhnS01fLzpDWOJA2Z3Qtn4xDHfiDaSnanerXE5pHaZkzXoZaNCiSMgMBaP995PjXpLOY7kv3/2Sf42cSW0KZ+r7KMyFIdWJ+DNmW/HbJM2ua333odtDgfh7rbFHOv4tWyKqcbP6eDwdrNko+ooo8g00gTq0bLHcQuKks9ETUAR59RwW9dHbH/aR6NRJjW2n2ISa5xQZIQNnG+hc9OvdM4DAiOkfnrle5p6LAN6/TFvmqwHEyFoSMYk+uldMy2PHmuutrZaFxYF5p0TcOuj4AFXp1dnAIhAKV9C5I1Oz4a0cxgJLrMENvsi0tul2yxCu4fMqDoTzgjUU+vfqxjbZL2vxZ8YSG/SvMnKdL9NYcLAA43aIdeLfvJij91opDrkE6gs/hCWWk3ml4CPYWN5HuAC0+T0hK/to4M55fGGvhQOTJlABTij7QxEW50CgqTFJoCJGw6xgI7VV3L68qlHy/klb8utyGPTXJW202NUNMDYnCyJ4sLEJy5+gxUEqa2syZEyD7k0vznRZh/BQHqJFjOY5xkp06YCaOQRA==; no-alert2=true; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1614239317,1614254565,1614308357,1614341349; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1614254245,1614305851,1614339942,1614341402; m=b4cc300eb53e14cc3852ecb84dae5183|1614358653000; sessionid=qtfru4f3w6wze29v6upfifqskr5vdang; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1614397831; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1614398338'
}
session = requests.Session()
session.headers = headers
session.post(logo_url)
response = session.get(url)
print(response.text)
print(response.cookies)
if __name__ == '__main__':
get_response(1)
测试之后发现headers很多不用带也可以,包括cookie甚至都可以全删减(因为sessionid会在session中自动保持),对端没有做验证;然后我们把题目要求的输出结果处理计算一下,代码最终如下:
import requests
import json
def get_response(page):
logo_url = 'http://match.yuanrenxue.com/logo'
url = f'http://match.yuanrenxue.com/api/match/3?page={page}'
headers = {
'User-Agent': 'yuanrenxue.project',
'Host': 'match.yuanrenxue.com',
'Connection': 'keep-alive',
'Content-Length': '0',
'Accept': '*/*',
'Origin': 'http://match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
session = requests.Session()
session.headers = headers
session.post(logo_url)
response = session.get(url)
return json.loads(response.text)
if __name__ == '__main__':
values = []
for i in range(1, 6):
data =get_response(i)['data']
for d in data:
values.append(d['value'])
print(max(values, key=values.count))
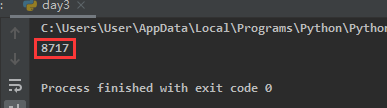
输出结果如下: