0x01 题目
0x02 步骤
1. F12开发者模式
刷新第一页,仔细研究发现里面有三次请求名为13的请求,根据题目提示cookie关键字,所以主要留意请求和响应的cookie值。
三次请求都带了sessionid,说明存在session(后面写代码要用session来写)。
另外,还都带了一个cookie键值:yuanrenxue_cookie,如下
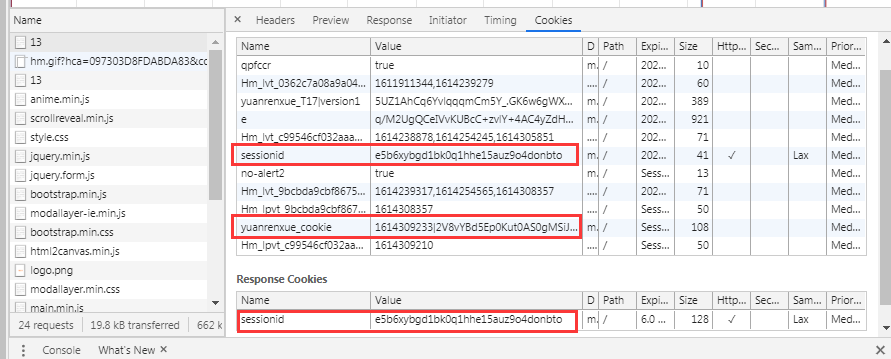
在这三个请求的响应中,可以看到,第一次请求看不到返回了什么,第二次请求返回页面结构,第三次请求是返回数据。
接下来就先找找yuanernxue_cookie这个是在哪里设置的。
2. 源码分析
右键查看源码,直接返回下面内容:
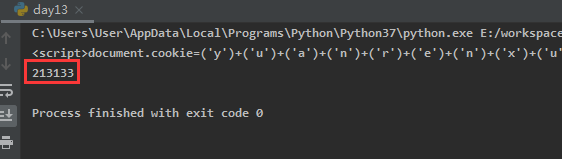
<script>document.cookie=('y')+('u')+('a')+('n')+('r')+('e')+('n')+('x')+('u')+('e')+('_')+('c')+('o')+('o')+('k')+('i')+('e')+('=')+('1')+('6')+('1')+('4')+('3')+('0')+('9')+('8')+('6')+('8')+('|')+('N')+('k')+('5')+('M')+('6')+('I')+('X')+('U')+('G')+('X')+('O')+('m')+('a')+('L')+('E')+('t')+('8')+('5')+('i')+('3')+('M')+('0')+('Y')+('6')+('R')+('m')+('8')+('y')+('b')+('G')+('N')+('u')+('O')+('R')+('W')+('E')+('J')+('a')+';path=/';location.href=location.pathname+location.search</script>
这个应该就是第一个请求中的代码,因为其他请求源码都不是这个。
代码是先设置两个cookie,直接在console中调试即可看到:

这里cookie值跟上面第一张图片中的不相等,是因为服务器有session时长,加载页面一小段时间后,我们再右键查看源码其实会重新获取session,也就是重新从第一次请求开始,所以返回的内容就是设置cookie的代码。
注意:如果在刷新页面后,立即右键查看源代码,看到的就是所有请求完成后的页面源码了。
接下来写个代码调试一下,用代码来获取其中的cookie,并添加到session中。
3. 编写代码
首先写第一次请求,是访问http://match.yuanrenxue.com/match/13,并且记住要用session建立连接,因为要保持连接状态,不然会重置cookie,如下:
import requests
import re
import json
def get_cookie():
url = f'http://match.yuanrenxue.com/match/13'
session = requests.Session()
response = session.get(url)
print(response.text)
if __name__ == '__main__':
get_cookie()
结果如图:

加个正则匹配一下,顺便设置到cookie中去:
import requests
import re
import json
def get_cookie():
url = f'http://match.yuanrenxue.com/match/13'
session = requests.Session()
response = session.get(url)
print(response.text)
s = ''.join(re.findall("\(\'([\w=|])\'\)", response.text))
print(s)
cookie_key, cookie_value = s.split('=')
session.cookies.set(cookie_key, cookie_value)
return session
if __name__ == '__main__':
session = get_cookie()
输出结果如下:

最后用设置好的session直接请求api:
import requests
import re
import json
def get_cookie():
url = f'http://match.yuanrenxue.com/match/13'
session = requests.Session()
response = session.get(url)
print(response.text)
s = ''.join(re.findall("\(\'([\w=|])\'\)", response.text))
cookie_key, cookie_value = s.split('=')
session.cookies.set(cookie_key, cookie_value)
return session
def get_response(session, page):
url = f'http://match.yuanrenxue.com/api/match/13?page={page}'
headers = {
'User-Agent': 'yuanrenxue.project',
}
response = session.get(url, headers=headers)
return json.loads(response.text)
if __name__ == '__main__':
session = get_cookie()
sum = 0
for i in range(1, 6):
data = get_response(session, i)['data']
for d in data:
sum += d['value']
print(sum)
输出结果: